What's inside this article:
- Basic information
- What is duplicated content?
- Add unique metadata for recorded Video shows
- Copy and clone content
Basic information
This article explains how you can avoid creating duplicated content using the tools available in Pangea CMS.
What is duplicated content?
Duplicated content occurs when the same content is available in more than one place on the internet. In this case, a "place" means a unique URL.
Search engines (such as Google) want to provide users with unique information. For this reason, search engines do not display duplicated content on results pages. When Google identifies a group of duplicated content:
- The URLs are grouped together and treated as a single piece of content.
- One URL is declared as the original version of the content.
- Only the URL for the original content is listed on results pages.
This means if search engines consider content to be duplicated, the content will not be listed on results pages and will be much harder to find.
Duplicated content falls into one of the following groups:
- Technical duplicates: Caused by URL variations. This might mean tracking IDs, identifiers for different versions of the same page (such as printer-friendly versions), and different protocols (HTTP / HTTPS).
- Editorial duplicates: Caused by editors copying content from other sources, or publishing multiple pages with identical metadata.
The Pangea team monitors sites for technical duplicates. We fix any issues that are caused by our code. Pangea CMS includes several tools to help sites avoid creating editorial duplicates. For details, review the sections below.
Add unique metadata for recorded Video shows
When you enable the Record option for a Video show via Scheduler & Template week, we strongly suggest selecting Draft under Record as.
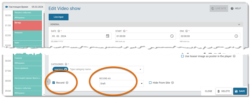
When the Draft option is selected, each recording is initially saved in Pangea CMS with the Draft status (the recording is not automatically published). You can then add unique metadata (title and introduction) before publishing the content. Each recording is saved in Pangea CMS as a Video.
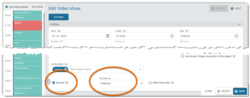
If you select Published, the recording is automatically published on the the public site. If every episode of the Video show has the same title and description, this approach creates many published content pages with the same metadata. Search engines treat these content pages as duplicates.
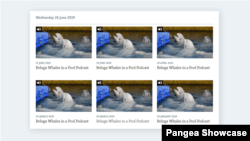
This approach might also reduce engagement with the content on your site. Consider that all recordings from the same Video show are listed together on the same Category page. If every item has the same title, visitors do not know what to expect from the episode.
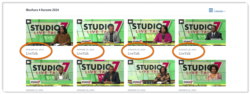
For each episode, consider adding a unique descriptor after the main title for the Video show. You can see an example of how this might look in the screenshot below.
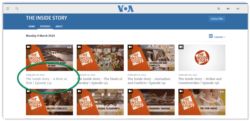
For detailed information about managing Video shows via Scheduler & Template week, see the following article:
Copy and clone content
Pangea CMS includes dedicated tools for copying / cloning content. Using these tools, you can copy / clone a content page that was originally published by another site. You can then adjust the content, and publish the content page on your own site.
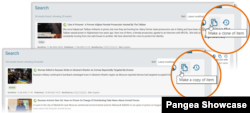
When you copy / clone a content page using the dedicated tools in Pangea CMS:
- In the metadata for the copy / clone, the URL for the original content page is added as the Canonical URL. This tells search engines which URL represents the original version of the content.
- Search engines only index the URL for the original version of the content page. This means that only the original version of the content page will be listed on search engine results pages.
If you plan to copy / clone a content page from another site without making significant changes to the content, we suggest using the dedicated tools in Pangea CMS. This represents good journalistic practice.
IMPORTANT: We do not suggest manually copying and publishing content from another site (unless you plan to make significant changes to the content).
To learn how to copy / clone content, see the following articles:

